InnoDB在处理更新语句的时候,并不会将数据直接更新到数据库,大量的磁盘操作势必影响数据库的性能,InnoDB是怎么做的呢?InnoDB通过引入内存组件buffer pool从而避免频繁对磁盘做随机读写操作,并引入redo log(写入日志)的机制保证了数据不丢失。采用缓存必然存在缓存不足需要进行内存淘汰,InnoDB则采取一种类似lru的内存淘汰算法。
本文将以InnoDB作为存储引擎的Mysql展开论述。
¶update语句执行过程如何上锁?
update语句在执行的时候则是当前读,得到最新的信息并且锁定相应的记录。一条update语句在执行过程中的锁定规则其实是依据InnoDB行锁规则。
InnoDB行锁是通过给索引上的索引项加锁来实现的,InnoDB这种行锁实现特点意味着:
只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
因此更新条件为非索引字段,行锁会升级成表锁。更新条件为索引字段时,行锁会锁定满足条件的行。
¶为什么写入缓存却可以保证数据不丢失?
数据写入缓存并不能保证数据不丢失,因此InnoDB引入了 redo log(重做日志)。
¶WAL
WAL的全称是Write-Ahead Logging,Mysql在更新数据时采用了一种日志先行的策略,先写日志,再写磁盘。
当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log里面,并更新内存,然后会在适当的时候,将这个操作记录更新到磁盘。
redo log记录的是相对mysql磁盘中的增量数据,可以保证即使数据库发生异常重启,内存中的数据清空了,之前提交的记录页不会丢失,具备crash-safe的能力。
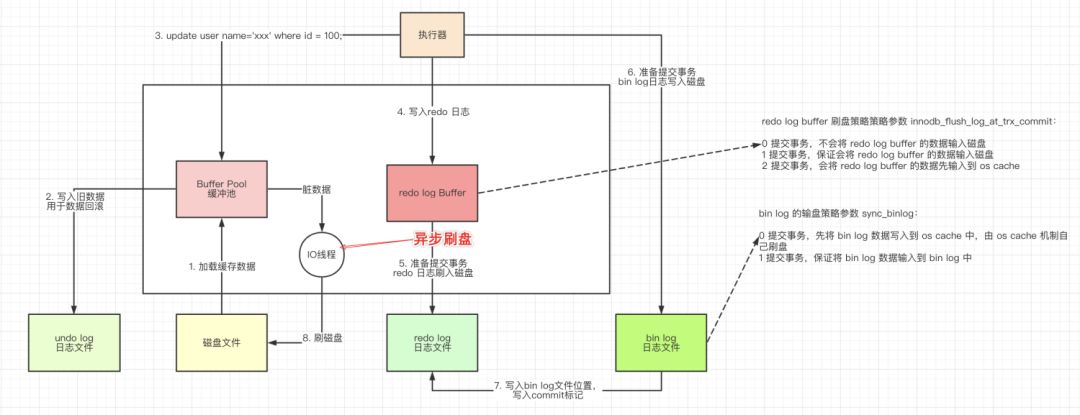
¶buffer pool 一探究竟
内存的数据页是在Buffer Pool 中管理的,通常以页(page)为单位缓存数据,每次读写数据都会通过 Buffer Pool。
在WAL里Buffer Pool 起到了加速更新的作用。同时查询数据时,当Buffer Pool 中存在用户所需要的数据时,直接返回。没有时才去硬盘中获取并更新Buffer Pool,也保证了查询的效率。
¶基本概念
数据在内存中更改后并不会立刻写入到磁盘中,这些数据被叫做脏数据。
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为脏页。
内存数据写入到磁盘后,内存和磁盘上的数据页的内容一致,称为干净页。
把内存里的数据写入磁盘的过程被称之为Flush。
通过 innodb_buffer_pool_size设置缓存的总容量。
mysql5.6 引入 innodb_buffer_pool_instances 可以设置多个缓冲池对象,此参数默认为8,主要目的是为了解决 互斥锁, 每个缓冲池管理其自己的空闲列表,提高查询并发性。
¶脏页刷新规则
mysql刷脏页会在以下四中场景下触发:
- 内存不够用: 如果内存不够用了会根据LRU算法淘汰旧数据,如果淘汰的是脏页必须先刷脏。
- redo log写满: redo log写满了,mysql必须停止所有的更新操作,然后把checkpoint往前推进,那么推进的这一部分对应的脏页都需要刷到磁盘上。
- mysql正常关闭: mysql正常关闭时后,会将内存中的脏页全部刷到磁盘上。
- mysql空闲时: mysql在服务器负载较小时会主动刷脏页。
当内存不足时,淘汰的数据页为脏页时,进行刷脏。redo log重放时,如果一个数据页已经是刷过,会识别出来并跳过。
¶InnoDB刷脏页的控制策略
通过设置innodb_io_capacity告知InnoDB你的磁盘能力,InnoDB会根据磁盘能力计算出刷盘的速率。建议设置成磁盘的IOPS。磁盘的 IOPS可以通过fio这个工具来测试
innodb_io_capacity设置过小会导致刷太慢,造成脏页累积,其次是redo log写满。所以,InnoDB的刷盘速度就是要参考这两个因素:一个是脏页比例,一个是redo log写盘速度。
参数:innodb_max_dirty_pages_pct 是脏页比例上限,默认值是75%。
脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的
¶连坐策略
MySQL中,刷脏页时,如果这个数据页旁边的数据页刚好是脏页,就会把旁边的脏页一并刷掉,而且这个逻辑还可以继续蔓延。
InnoDB中的innodb_flush_neighbors 参数就是用来控制这个行为的,值为1的时候会有上述的连坐机制,值为0时表示不会蔓延。
这种机制的优化在机械硬盘时代是很有意义的,可以减少很多随机IO。当使用的是SSD这类IOPS比较高的设备的话,随机IO并非瓶颈,建议设置成0。
¶内存淘汰策略
而Buffer Pool的存在对查询起到加速效果,但如果多次查询都没有命中,内存命中率不高其实就没有太大意义了,通过show engine innodb status可以查看BP命中率。
InnoDB 的Buffer Pool的大小是由参数 innodb_buffer_pool_size确定的,一般建议设置成可用物理内存的60%~80%。Buffer Pool满了,而又要从磁盘读入一个数据页,那肯定是要淘汰一个旧数据页的。一个好的淘汰策略会极大的影响之后查询的内存命中率。
InnoDB内存管理使用的是LRU算法,但在此基础上做了一些改进。
¶为什么不能直接使用LRU算法
LRU算法一般会使用链表和hash来实现。新的数据会写入到链表的头部,当遭遇内存不足时,会将尾部数据进行淘汰。
在mysql中,该算法看似可以满足。但是mysql中出现全表扫描时,表数据特别大,便会把当前的Buffer Pool里的数据全部淘汰掉,存入扫描过程中访问到的数据页的内容。
但该表数据在平时业务场景下并不会访问,加载到Buffer Pool中的页并没有被使用,最终便会导致Buffer Pool的内存命中率急剧下降,磁盘压力增加,SQL语句响应变慢。
¶分层的LRU算法
正是存在大量的使用频率偏低的页被同时加载到Buffer Pool时,可能会把那些使用频率非常高的页从Buffer Pool中淘汰掉的情况。Mysql按照5:3(innodb_old_blocks_pct参数控制)的比例把整个LRU链表分成了young区域和old区域。
改进后的LRU算法执行流:
- 磁盘中页数据第一次加载到内存中时,先缓存到链表old区的头部,这样预读的数据没使用的话,就会逐渐被淘汰掉;且不会影响到young区域中使用频繁的缓存数据。
- 处于old区域的数据页,第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间间隔在1秒(时间由参数 innodb_old_blocks_time 控制,默认值是1000,单位毫秒)以内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。
为什么需要引入innodb_old_blocks_time的机制呢?
一个数据页里面有多条记录被访问,这个数据页也会被多次访问,当数据库在处理全表扫描时,一个数据页里面有多条记录,这个数据页会被多次访问,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔会很短。因此还是保证这次查询时数据页仍就被保留在old区域。
通过优化后的LRU算法在扫描大表的过程中,虽然也用到了Buffer Pool,但是对young区域完全没有影响,从而保证Buffer Pool的缓存命中率。
参考:
mysql 45讲 - 02讲日志系统:一条SQL更新语句是如何执行的
mysql 45讲 - 12讲为什么我的MySQL会“抖”一下
mysql 45讲 - 33讲我查这么多数据,会不会把数据库内存打爆